
ステータス
解決
事象
2023年1月2日正午頃、https://bmf-tech.com/ にアクセスするとレスポンスが遅い、500エラーが常に返却されることに気づき、発覚。
grafanaにログインして調査をしようとしたが、ログインができなかった。
一部コンテナが何らかの原因でダウンした可能性を考慮して、デプロイを実施したが、no space left on device のエラーログを確認したため、別の原因であることを推察。
影響
bmf-techの全サービスが利用できない状況となった。
Nginxのリクエスト状況を確認するに、2023年1月2日午前5時48分頃からサービスダウンしていた。
復旧は同日12時40分頃。
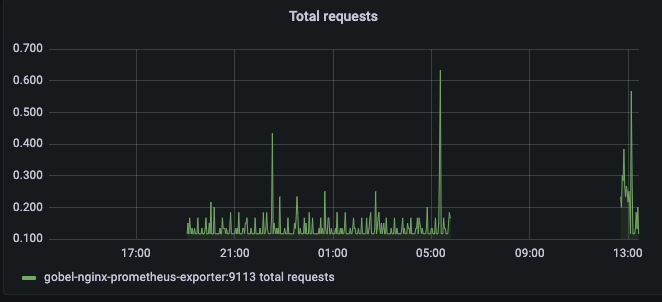
2023年1月2日午前5時48分頃~12時40分頃までの間に58件の500エラーが発生。 ※ある程度のユーザー数を計測したかったが、ログやGA4などから集計できるように調整していないため調査しづらい。
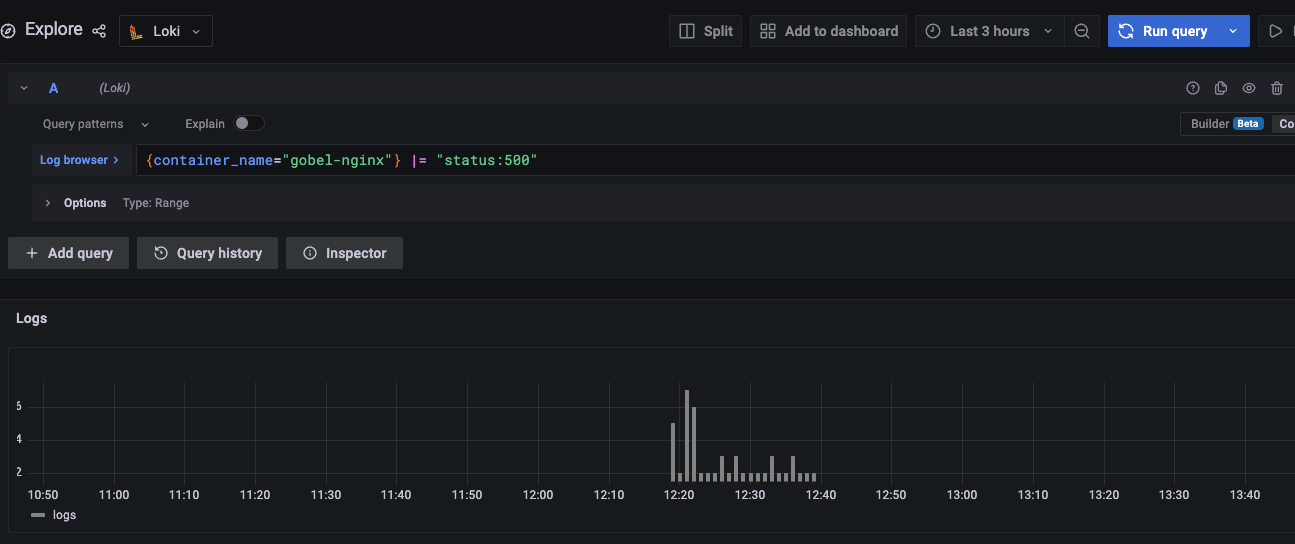
原因
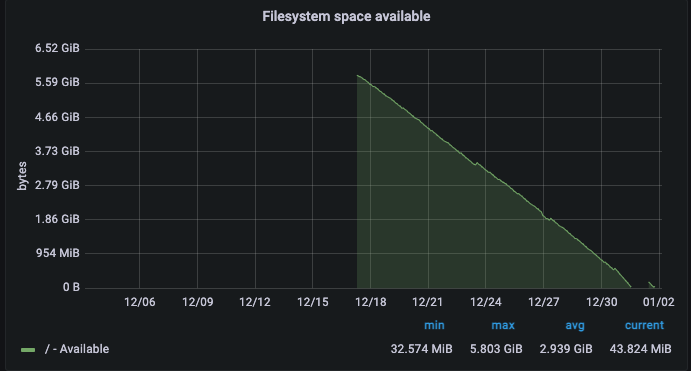
ファイルシステムに空きがないのが原因であった。
対応
ファイルシステム容量を圧迫しているデータを削除し、空き容量を確保。
アクション
- サーバーにsshし、dfコマンドでディスクの空き容量を確認。空き容量がなかった。
df -h
- duコマンドでディスクを一番使っていそうな箇所を調査。
/var/lib/docker/配下であると特定。
du -sh /var/lib/docker*
- 使用されていないdockerオブジェクトを削除して、空き容量を確保。
docker system prune -a
- ついでに2番目くらいに容量を食っていたjournalのログも200M残して削除。
journalctl --vacuum-size=200M
追記
上記の対応だけでは不十分だった。
/var/lib/docker/containers 配下に溜まっているログファイルが容量を大きく取っていたので、コンテナのログローテーションを調整することで対応した。
ex.
app:
container_name: "app"
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}|{{.ImageFullID}}|{{.FullID}}"
max-size: "10m" // ロールオーバーするファイルサイズ
max-file: "3" // ログが何回ロールオーバされたら破棄するか
この対応により容量に大きく余裕を持つことができた。一番のボトルネックがここであったということ。。。
再発防止
ファイルシステムの利用率をアラートに追加。事前に逼迫を検知して対処できるようにした。

その他
削除できるデータやローテーションすべきデータを洗い出して節約できるようにしたい。
所感
bmf-techをリプレースして以来、初めての障害であった。